
Elasticsearch & Spring Boot – Premiers pas (Partie 2)
Dans le précédent article, nous avons découvert comment intégrer Elasticsearch avec Spring Boot pour profiter de ses capacités de recherche full-text.
Mais dans les environnements professionnels, Elasticsearch prend toute sa dimension lorsqu’il est intégré à la stack ELK : Elasticsearch, Logstash, et Kibana.
Cet ensemble d’outils open-source est devenu incontournable pour centraliser, analyser et visualiser des données massives, souvent issues de logs applicatifs ou systèmes.
Présentation de la stack ELK
Elasticsearch
Cœur de la stack, **Elasticsearch** indexe et recherche dans d’énormes volumes de données à faible latence.
Il ne se limite pas à du texte brut : logs, métriques, documents JSON, événements métiers… tout peut être indexé pour permettre recherche et analyse.
Logstash
**Logstash** est le collecteur et transformateur de données.
Il récupère les données depuis diverses sources (fichiers, bases, APIs, systèmes de messagerie comme Kafka), les transforme (parse, enrichissement, filtrage), puis les envoie vers **Elasticsearch**.
Sa configuration repose sur trois sections clés :
- **Input** : où et comment lire les données.
- **Filter** : transformations appliquées (parsing de logs, ajout de champs, anonymisation…).
- **Output** : où envoyer les données (souvent Elasticsearch, mais aussi d’autres destinations).
Kibana
**Kibana** est l’interface visuelle de la stack.
Il permet de créer tableaux de bord, graphiques, cartes interactives et filtres de recherche pour explorer les données indexées dans **Elasticsearch**.
Kibana transforme ainsi des millions de lignes de logs bruts en indicateurs clairs et exploitables.
Passer les logs Spring Boot au format ECS
Par défaut, Spring Boot utilise une sortie de logs en texte brut avec un pattern lisible par l’humain :
2025-08-12T12:33:46.624+02:00 INFO 60795 --- [ main] fr.eletutour.JasperApplication : Started JasperApplication in 1.579 seconds (process running for 1.742)
Ce format est pratique pour la lecture directe en console, mais peu adapté aux systèmes de collecte et d’analyse automatisés comme ELK.
Pour exploiter pleinement la puissance d’Elasticsearch et de Kibana, il est préférable d’adopter un format standardisé et structuré, tel que **ECS – Elastic Common Schema**.
Qu’est-ce que l’ECS ?
L’ECS (Elastic Common Schema) est une convention proposée par Elastic pour normaliser la structure des données envoyées vers Elasticsearch.
Il définit un ensemble de champs standard (timestamp, host, event, log.level, message…) qui facilitent la corrélation et la recherche à travers différentes sources de données.
Avec ECS, les logs de multiples applications peuvent être agrégés et analysés de manière cohérente.
Utiliser un encodeur JSON compatible ECS avec Spring Boot
Pour que la configuration logback.xml fonctionne avec l’encodage ECS et l’envoi des logs vers Logstash, deux bibliothèques sont nécessaires :
<dependency>
<groupId>co.elastic.logging</groupId>
<artifactId>logback-ecs-encoder</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>8.1</version>
</dependency>
**Rôle de chaque dépendance :**
**logback-ecs-encoder**(co.elastic.logging)
Permet de formater les logs selon le format **ECS (Elastic Common Schema)** utilisé par Elasticsearch et Kibana.
Dans votre configuration, c’est la classeco.elastic.logging.logback.EcsEncoderqui encode chaque log pour qu’il soit structuré et directement exploitable dans l’Elastic Stack.**logstash-logback-encoder**(net.logstash.logback)
Fournit des appenders et des encodeurs supplémentaires pour **Logback**, dont leLogstashTcpSocketAppenderqui envoie les logs directement vers un serveur Logstash via TCP.
Il permet aussi de gérer la sérialisation JSON et l’ajout d’informations enrichies (MDC, champs personnalisés, etc.).
Configurer Logback pour produire du JSON ECS
Pour bénéficier à la fois du format **ECS** (Elastic Common Schema) et de l’envoi direct des logs vers Logstash, nous allons utiliser deux bibliothèques complémentaires :
**co.elastic.logging:ecs-logging-logback**: fournit l’encodeurEcsEncoder, qui formate les logs au standard ECS.**net.logstash.logback:logstash-logback-encoder**: offre les appenders et encodeurs nécessaires pour envoyer les logs vers **Logstash**.
Ces deux dépendances peuvent cohabiter dans la même configuration **Logback, ce qui nous permet de profiter du meilleur des deux mondes :
📜 un format structuré ECS + 📡 un transport optimisé vers **Logstash**.
Voici un exemple complet de configuration logback-spring.xml :
<configuration>
<springProperty scope="context" name="LOGSTASH_HOST" source="logging.logstash.host"/>
<springProperty scope="context" name="LOGSTASH_PORT" source="logging.logstash.port"/>
<springProperty scope="context" name="SERVICE_NAME" source="spring.application.name"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="co.elastic.logging.logback.EcsEncoder">
<serviceName>${SERVICE_NAME}</serviceName>
</encoder>
</appender>
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>${LOGSTASH_HOST}:${LOGSTASH_PORT}</destination>
<encoder class="co.elastic.logging.logback.EcsEncoder">
<serviceName>${SERVICE_NAME}</serviceName>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
**Explication de la configuration**
- **Propriétés Spring**
-
LOGSTASH_HOSTetLOGSTASH_PORTsont récupérés depuis le fichierapplication.properties(logging.logstash.hostetlogging.logstash.port).SERVICE_NAMEest alimenté parspring.application.name, ce qui permet d’ajouter le nom du service dans chaque log.
- **Appender CONSOLE**
-
- Utilise
EcsEncoderpour produire un log structuré ECS directement dans la console.
- Utilise
- **Appender LOGSTASH**
-
- Établit une connexion TCP vers Logstash.
- Formate également les logs en ECS avant envoi, garantissant une cohérence entre la sortie console et l’ingestion par Logstash.
Avec cette configuration, chaque ligne de log devient un objet JSON conforme à ECS, **prêt à être interprété par Logstash**.
{"@timestamp":"2025-08-12T10:41:13.567Z","log.level": "INFO","message":"Started ElasticSearchApplication in 1.846 seconds (process running for 2.002)","ecs.version": "1.2.0","service.name":"elasticsearch-tutorial","event.dataset":"elasticsearch-tutorial","process.thread.name":"main","log.logger":"fr.eletutour.elastic.ElasticSearchApplication"}
Configuration de Logstash
Pour collecter et acheminer les logs émis par notre application Spring Boot vers **Elasticsearch**, nous utilisons une configuration Logstash simple mais efficace.
**Définition de l’entrée (****input****)**
input {
tcp {
port => 5044
codec => json_lines
}
}
Ici, Logstash écoute sur le port **5044** et attend des flux entrants au format **JSON Lines** (json_lines).
- **port 5044** : correspond au port sur lequel notre application (via Logback et l’appender Logstash) envoie les logs.
- **codec json_lines** : permet de traiter chaque ligne comme un objet JSON indépendant, format idéal pour les événements de log structurés.
**Définition de la sortie (****output****)**
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
user => "elastic"
password => "changeme"
index => "springboot-logs-%{+YYYY.MM.dd}"
}
}
Cette section indique que les logs seront envoyés vers un cluster **Elasticsearch** :
- **hosts** : l’URL du nœud Elasticsearch (ici, un conteneur local nommé
elasticsearch). - **user** / **password** : les identifiants utilisés pour se connecter au cluster.
- **index** : le nom de l’index dans lequel les logs seront stockés. La syntaxe
%{+YYYY.MM.dd}permet de créer un index journalier, ce qui facilite la gestion et la rétention des données.
Grâce à cette configuration, les logs produits par notre application transitent de la manière suivante :
**Spring Boot → Logback (ECS Encoder) → Logstash (TCP 5044) → Elasticsearch (index journalier)**.
Visualisation des logs dans Kibana
Maintenant que nos logs sont indexées dans Elasticsearch, il nous reste plus qu’à les visualiser dans **Kibana**.
Pour ce faire, il faut :
- Nous connecter à notre instance de Kibana
- Aller dans **stack management**
/app/management - Sélectionner **Data Views** dans le menu et cliquer sur Create Data View
Dans la fenetre qui s’ouvre il faut alors renseigner le nom des indexs que l’on veut visualiser.
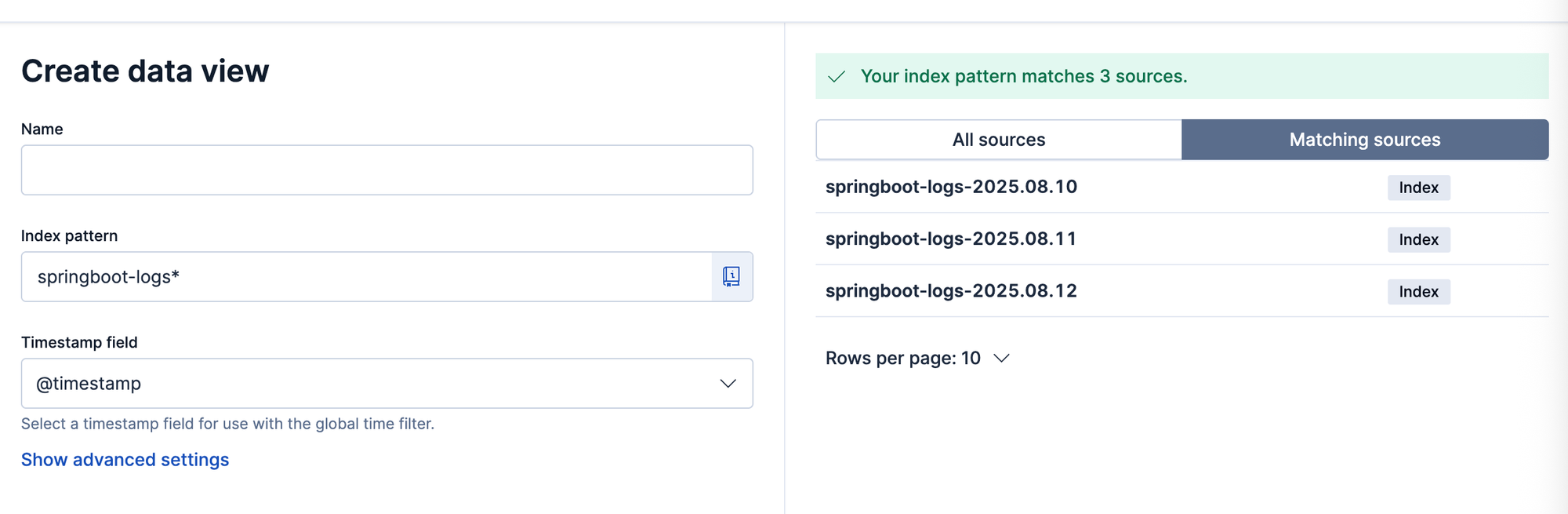
Comme précédemment nous avons paramétré des index journaliers, je retrouve ici différents index qui correspondent au pattern renseigné.
Une fois cela fait je peux sauvegarder.
Il ne me reste plus qu’a accéder à la vue discover et de sélectionner la vue que souhaite visualiser (ici celle créer précédemment).
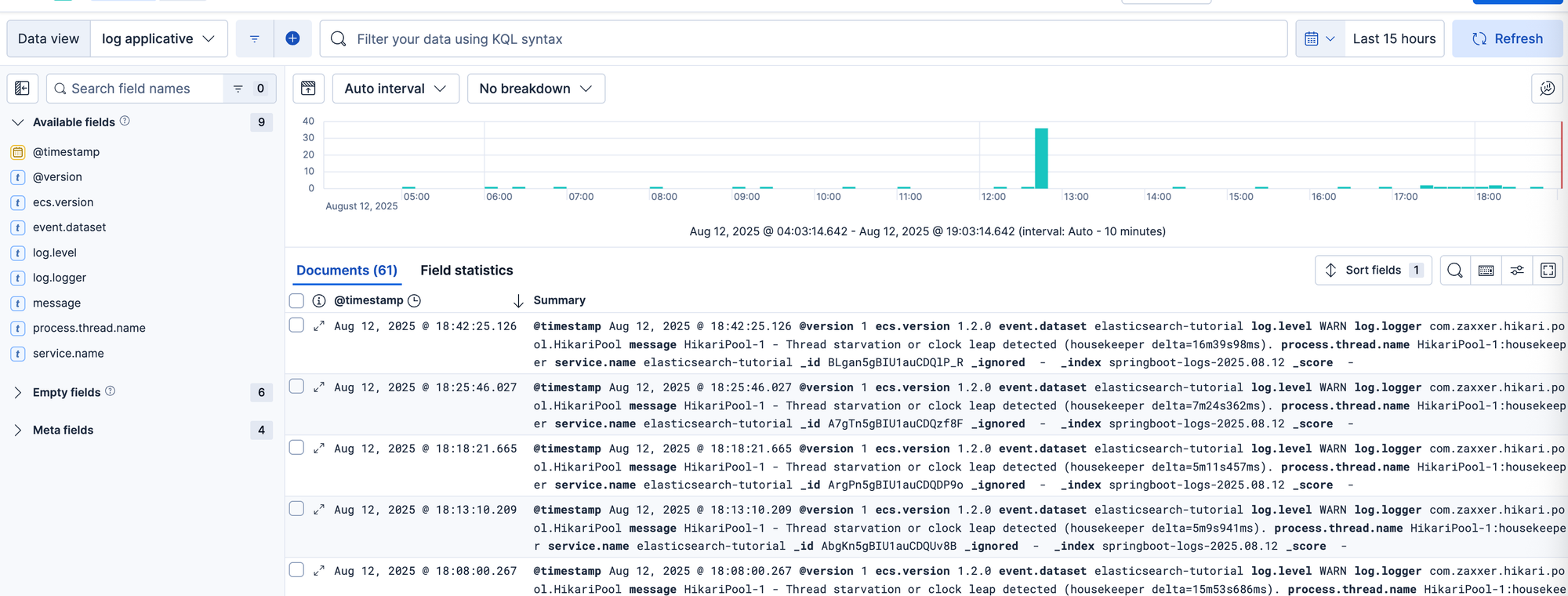
Je peux alors filtrer mes résultat sur une plage de temps, ou bien la valeur d’un des champs de mon index.
Conclusion
En intégrant **Logback, **Logstash** et **Elasticsearch** au sein d’une application Spring Boot, nous mettons en place une chaîne de collecte et d’analyse des logs à la fois robuste et évolutive. Les journaux, autrefois simples lignes de texte dans un fichier, deviennent de véritables **sources d’information exploitables**, capables d’éclairer les décisions techniques et de faciliter le diagnostic des incidents.
Cette approche s’inscrit dans une tradition bien établie du développement logiciel : **observer, mesurer, comprendre, puis agir**. Que l’on soit dans un contexte de production à forte charge ou dans un environnement de anté prod, disposer d’une vision claire et centralisée des événements applicatifs est un atout stratégique.